
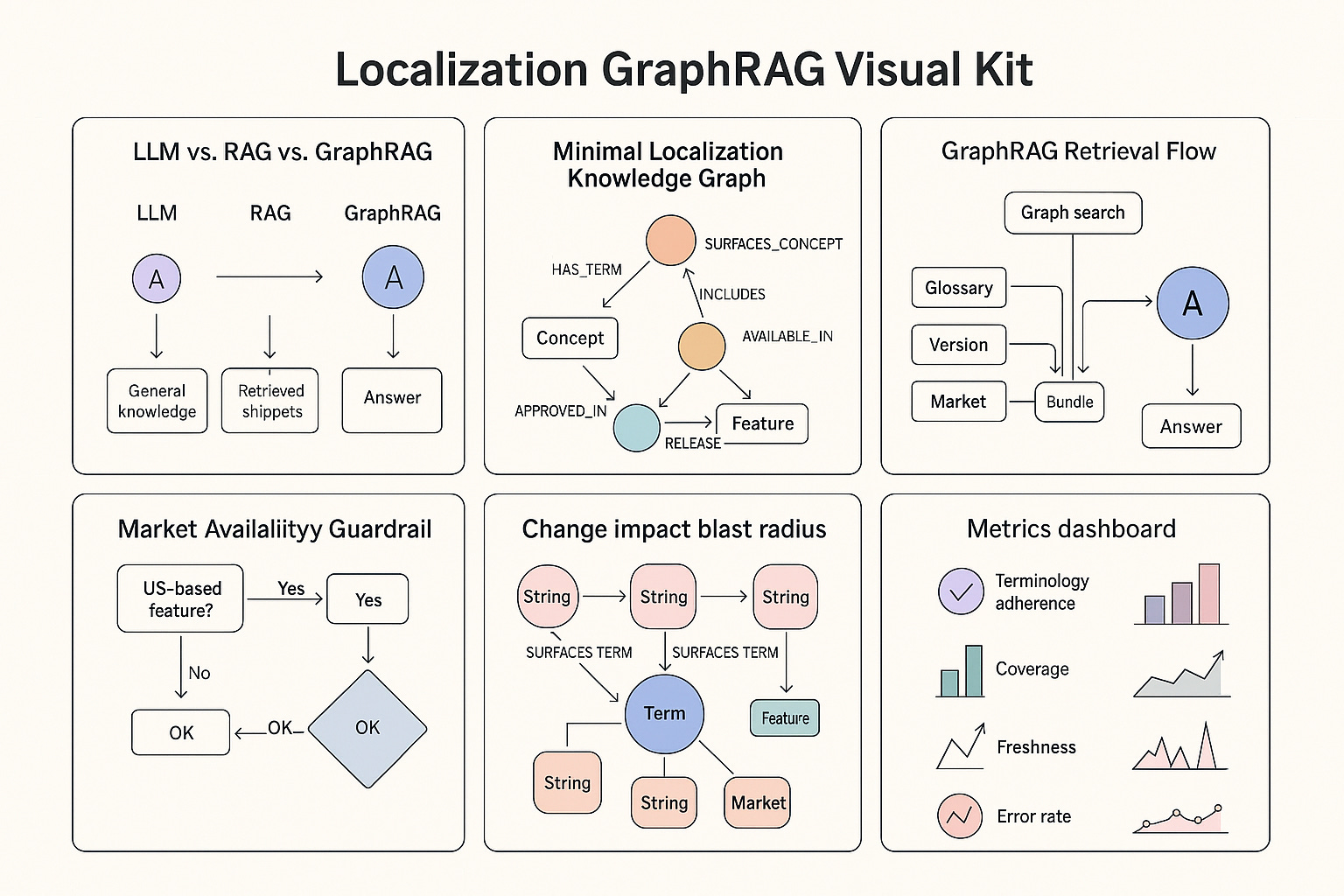
Why Retrieval-Augmented Generation (RAG) Needs Knowledge Graphs
and Why It Matters for Localization

Large language models (LLMs) like GPT-4 changed how we work with text, from drafting UX copy to generating code. But if you’ve tried to use them in production for internationalization (i18n) and localization (L10N), you’ve hit the edges fast: knowledge cutoffs, confident hallucinations, and no native access to your private translation memories, glossaries, release notes, or market-availability rules.
The short version
LLM alone: beautiful language, brittle facts.
LLM + RAG: grounds answers in your sources (TMs, glossaries, docs).
LLM + GraphRAG: adds relationships (who/what/where/when/why) so answers are current, consistent, explainable, and aligned with market constraints and style rules.
If you care about meaning, context, and culture at scale, GraphRAG is the step change.
LLMs predict the next token. They don’t store truth like a database.
Knowledge cutoff: Ask about iOS string guidelines after a 2024 update; the model can sound right and still be wrong.
Stale facts: A product is rebranded in JP; the model keeps the old name and replicates inconsistency across locales.
Hallucinations: It invents a TM entry or a French glossary term that never existed.
No private data: Out of the box, it can’t answer: “Which of our locales enforces formal address in error messages?” or “Which features are available in ES vs. MX?”
Two Paths to Fill the Gap
1) Supervised Fine-Tuning
Teach the model with curated Q&A.
Pros: can shift tone/formatting; useful for narrow tasks.
Cons: costly; retraining for every glossary/style change is unrealistic.
2) Retrieval-Augmented Generation (RAG)
At query time, retrieve relevant snippets (TM entries, glossaries, release notes, style guides) and inject them into the prompt.
Result: fewer hallucinations, answers tied to sources, always current—no retraining.
Localization example
“What’s our approved ES translation for log out across mobile apps?”
RAG fetches the glossary + TM + product-specific notes and the LLM answers with traceable citations.
Why Knowledge Graphs Supercharge RAG (GraphRAG)
Classic RAG treats your world as a pile of text chunks. Your company’s content isn’t a pile, it’s a network of meaning:
Terms connect to concepts.
Concepts connect to features and releases.
Markets constrain features (and strings) by availability and regulation.
Style and tone rules differ per locale/persona/channel.
TMs and screenshots tie back to versions and platforms.
A knowledge graph maps entities (Concept, TermVariant, Locale, Feature, Release, Persona…) and relationships (APPROVED_IN, PART_OF, AVAILABLE_IN, REQUIRES_FORMAL_ADDRESS, DEPRECATES, CONFLICTS_WITH…).
GraphRAG retrieves nodes + edges (not just text), so the LLM reasons with structure and context.
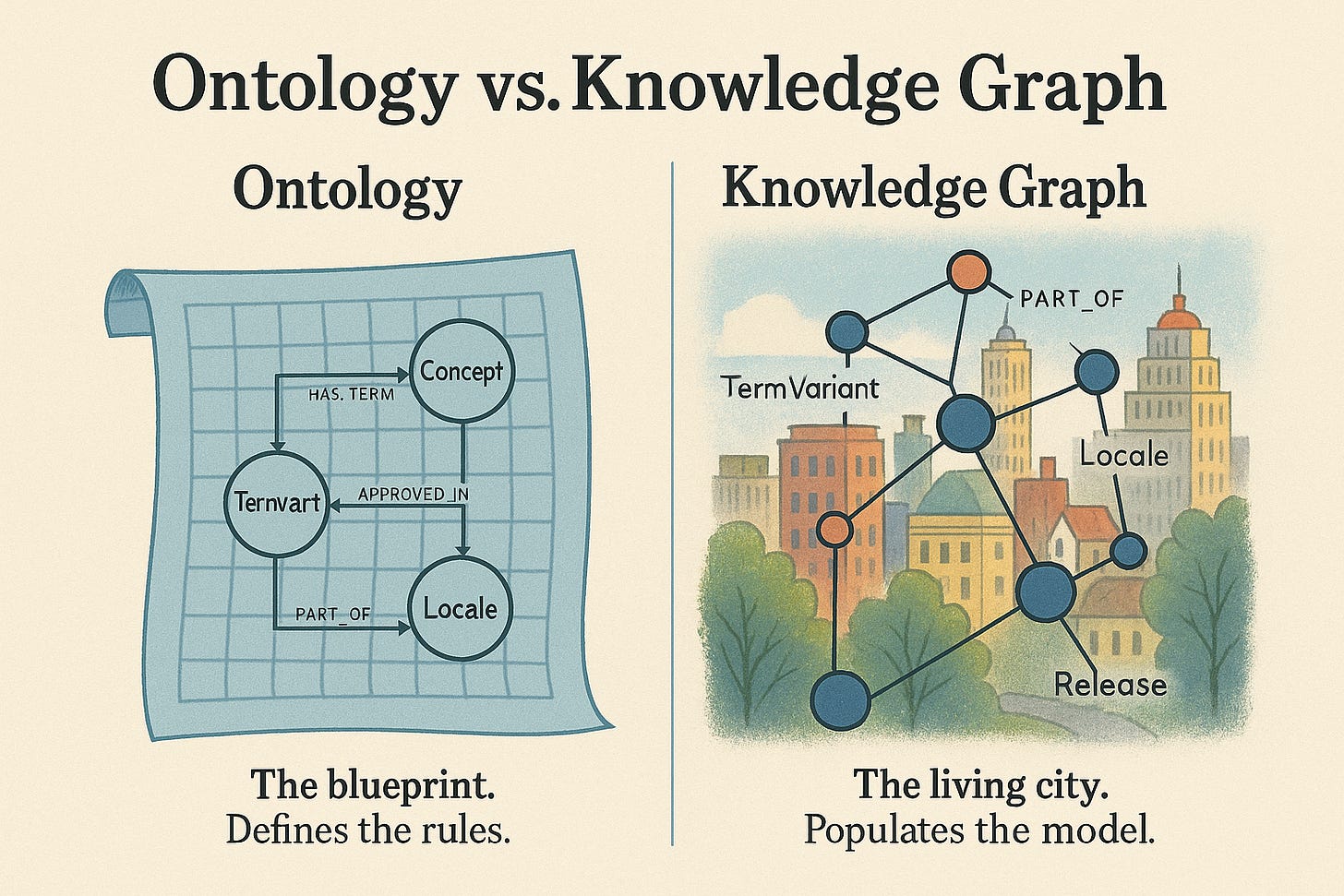
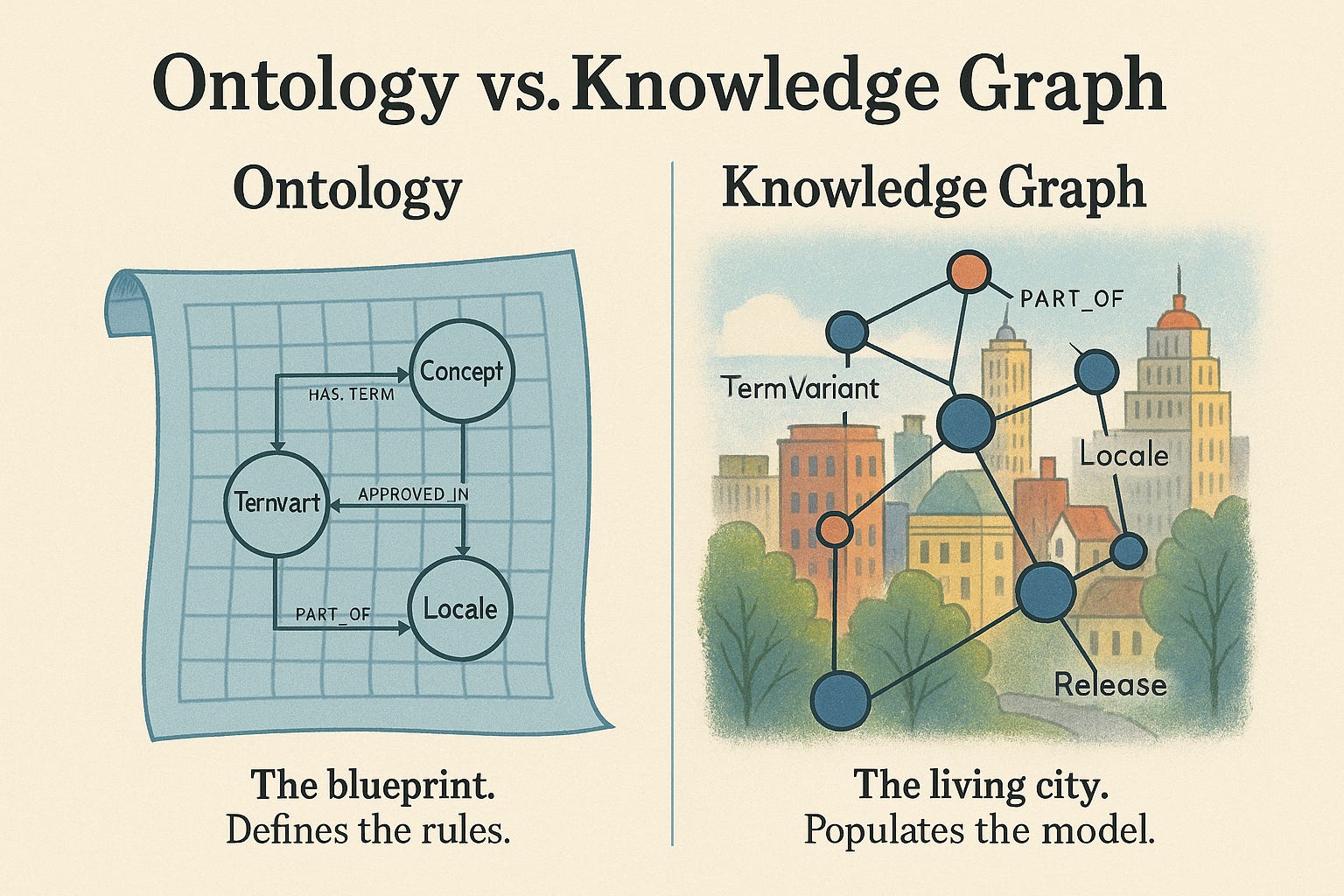
Wait—What About Ontologies? Aren’t They the Same as Knowledge Graphs?
Ontology and knowledge graph are often used interchangeably in AI/semantic tech circles, but they are not the same. Let’s break it down clearly:
Ontology = The Blueprint
An ontology is a formal specification of concepts, entities, and the relationships between them.
Abstract: it’s the design, schema, or rules of the game.
Defines types of things (Concept, TermVariant, Locale, Release).
Defines types of relationships (HAS_TERM, APPROVED_IN, AVAILABLE_IN).
Specifies constraints (e.g., a TermVariant must be APPROVED_IN at least one Locale).
Philosophical root: ontology comes from metaphysics — the study of “what exists” and “how it relates.”
👉 In L10N/i18n:
Your ontology says:
A
Concepthas one or moreTermVariants.A
TermVariantis linked to aLocale.A
Featuremay beAVAILABLE_INcertain markets.A
StyleRuleapplies to aLocale+Persona.
It doesn’t yet say which concepts, which terms, or which markets. It’s just the framework.
2. Knowledge Graph = The Living Instance
A knowledge graph is the real, populated data structure that follows the ontology’s rules.
Concrete: it’s your ontology brought to life with actual nodes and edges.
Contains facts (Concept = “LOG_OUT”, TermVariant = “Cerrar sesión”, Locale = “es-ES”).
Dynamic: can evolve over time, pulling data from TMs, glossaries, release notes, feature flags.
Queryable: you can ask it questions like:
“Which features are AVAILABLE_IN MX?”
“Show me all APPROVED_IN TermVariants for Concept = ‘Sign up’ in Japanese.”
👉 In L10N/i18n:
Your knowledge graph is full of data like:
Concept = LOG_OUT→HAS_TERM = “Cerrar sesión”→Locale = es-ES→APPROVED_IN = 2024 Release v3.2.Feature = ID_SCAN→AVAILABLE_IN = es-ESbutNOT_AVAILABLE_IN = es-MX.
This is what the LLM (via GraphRAG) retrieves from.
3. How They Work Together
Ontology without a knowledge graph = empty blueprint. Elegant, but useless on its own.
Knowledge graph without ontology = spaghetti graph. Lots of facts, no structure, no consistency.
Together:
Ontology = grammar (rules of the language).
Knowledge Graph = sentence (actual expression of meaning).
Or, using a metaphor:
Ontology = the city’s zoning plan (where houses, roads, parks should be).
Knowledge Graph = the built city (the houses, roads, parks actually there).
4. Why This Matters for GraphRAG in L10N/i18n
Without an ontology, your knowledge graph won’t scale (every PM structures things differently, relationships get messy, contradictions appear).
Without a knowledge graph, your ontology is just theory (no usable data for the LLM).
GraphRAG only works if you have both:
Ontology ensures retrieval is structured and consistent.
Knowledge graph provides the actual context (terms, releases, locales, rules).
5. Quick Analogy Table

✅ In short:
Ontology = schema, categories, constraints.
Knowledge Graph = data + relationships following that schema.
GraphRAG = LLM grounded in that graph.
So: ontology first (design the model), then knowledge graph (fill it with your real content).
Without an ontology, your knowledge graph risks becoming inconsistent spaghetti. Without a knowledge graph, your ontology is just theory. Together, they power GraphRAG.
Concrete Wins for L10N/i18n
Consistency: One concept → many locale-specific terms → enforced across apps/products.
Freshness: Link strings to releases; when a feature deprecates, dependent UI copy is flagged.
Market truth: Copy reflects availability rules (only mention “Scan ID” where KYC is live).
Explainability: Every claim points back to graph nodes (glossary entry X, rule Y, release Z).
Start small. Model the minimum that explains real decisions:
Core entities (nodes)
Concept (canonical meaning)
TermVariant (language, script, case, morphology, gender)
Locale (BCP-47, region, writing system)
Product / Feature / Plan
Release (version, date, channels)
StyleRule / ToneRule
TMEntry / GlossaryEntry (with sources)
MarketAvailability / LegalConstraint
Persona (voice calibration)
Key relationships (edges)
Concept —HAS_TERM→ TermVariant
TermVariant —APPROVED_IN→ Locale
Feature —SURFACES_CONCEPT→ Concept
Feature —AVAILABLE_IN→ Plan
Release —INCLUDES→ Feature
StyleRule —APPLIES_TO→ Locale (and optionally Persona/Channel)
LegalConstraint —RESTRICTS→ Feature / CopyUnit
This already answers high-value questions like:
“Show me all German terms with gendered forms for Account/Owner.”
“Which ES-MX strings must not mention Feature X because it’s not available in MX?”
“What’s the approved Log out translation in ES-ES across mobile, with last-reviewed date and source?”
GraphRAG in Practice
Ingest & Normalize: Parse TMs, glossaries, style guides, release notes, screenshots → turn into nodes/edges.
Retrieve (Hybrid): Keyword + vector search → expand over graph → find related nodes.
Compose Context: Bundle relevant nodes + shortest path explanations.
Generate with Guardrails: Force citations, enforce constraints, reject uncited claims.
Implementation Checklist
Inventory sources (TMs, glossaries, style guides, release notes, market constraints).
Define a minimal ontology first.
Load data into a graph database (Neo4j is popular).
Add embeddings for semantic search.
Stand up GraphRAG retrieval pipeline.
Wrap generation with policies (hard constraints + citations).
Measure terminology adherence, coverage, freshness, error rate.
GraphRAG really begins to shine when applied to the everyday challenges of global teams. It makes copy release-aware: only mentioning a feature in locales Y and Z once version 3.2 has shipped. It adapts tone by market, switching to informal Spanish for LatAm while staying formal in German push notifications. It offers explainability for reviewers, since every translation can cite the concept, the approval step, the last reviewer, and the release scope. And it helps with change management, because when a term changes, the graph can instantly show the blast radius across features, strings, and markets.
Of course, there are pitfalls to avoid. Without structure, you fall into “chunk soup,” where vectorized text becomes useless because relationships aren’t modeled. Without versioning, you end up with untrustworthy truth—terms must always be tied to releases and owners. If you don’t enforce hard constraints, market and legal rules slip from mandatory guardrails into mere suggestions. And if you don’t preserve provenance, reviewers are left in the dark—sources must always be cited.
The future of accurate, explainable, culturally aware AI isn’t “bigger models”, it’s smarter retrieval. For i18n and L10N, GraphRAG lets you ground generation in meaning (concepts), context (relationships), and culture (locale rules).
Your ontology defines the structure, your knowledge graph fills it with life, and GraphRAG makes it usable by AI. That’s how you get systems that don’t just speak multiple languages, they respect them.
👉 Next up in new The AI Ready Localizer: Building a Localization Knowledge Graph step by step.
If this was useful, give it a little ❤️ or share it around—helps more people in L10N/i18n find it, and I’d love to hear what you think too.
Insightful!
Great breakdown! Would love to know your point of view on chunking and embeddings in this context 💡