

Welcome to the era of Self-RAG and Agentic RAG—two powerful evolutions of Retrieval-Augmented Generation (RAG) that could quietly revolutionize how localization teams work with content, context, and scale.

Let’s break it down:
First, a quick recap:
Standard RAG is like asking an intern to Google something and write you a quick blurb.
Self-RAG is that intern double-checking their own work, realizing the sources were flimsy, and giving it another go.
Agentic RAG? That’s a project manager who breaks the task into steps, asks clarifying questions, gathers more sources, and only then delivers a thoughtful response.
Why does this matter to localization?
Because traditional localization is filled with repetitive tasks that rely on static inputs: source strings, TMs, termbases, and scattered context. But with RAG variants, we can do so much more than just “translate what’s there.”
Here’s how they map to our world:
1. Standard RAG in Localization
Used for: automated responses, glossary lookup, contextual TM suggestions.
Limitation: One-shot and context-blind.
Analogy: “Translate this string using whatever’s in the memory.”
Example: A chatbot suggesting translations for “Cancel” based on TM hits—without checking where it appears.
2. Self-RAG in Localization
Used for: in-context QA, self-validating glossary compliance, adaptive translation suggestions.
Process:
Retrieves content and generates a localized version.
Reflects: “Does this align with the glossary? Does this fit the design context?”
If not, it refines the search and tries again.
Use Case: Terminology validation agents that rewrite prompts until the right glossary term appears naturally in context. Think of this as a QA linguist built into your AI assistant.
3. Agentic RAG in Localization
Used for: content restructuring, multi-market adaptation, full in-context review workflows.
More proactive:
Breaks complex input into segments (UI string, help text, CTA, tone).
Plans what needs to be retrieved: tone guides, brand voice samples, screenshots, TM history.
Iterates through each step until the adaptation is ready.
Use Case: A localization copilot that asks:
“Is this tone too formal for Spain?”
“What’s the past usage of this term in marketing campaigns?”
“Does this CTA fit inside the button width for Japanese?”
This is the dream L10N assistant—one that doesn’t just guess, but plans, checks, and delivers.
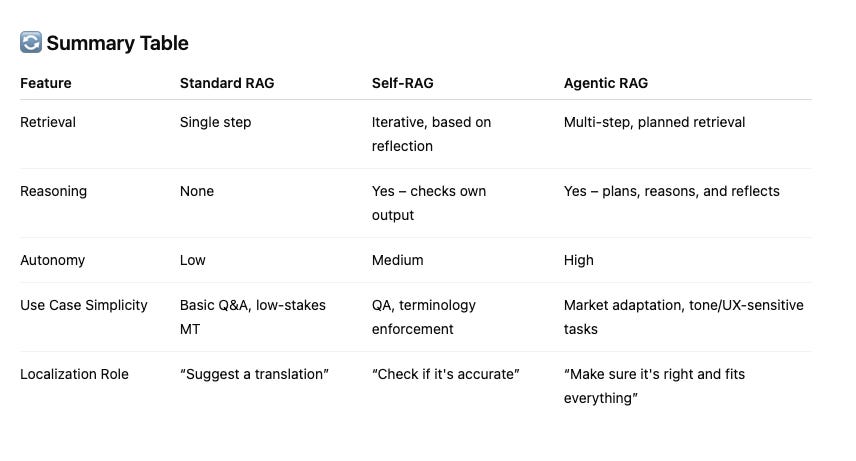
So which should we aim for?
Need high precision for terminology, regulated markets, or UI strings? → Self-RAG is your best bet.
Need flexibility for campaigns, emerging markets, or tone-sensitive content? → Agentic RAG will shine.
Right now, Agentic RAG is already powering localization-adjacent tools like LangChain, AutoGPT, CrewAI—just not marketed as “localization tech.”
Meanwhile, Self-RAG is still the clever researcher in the lab, brilliant but not yet baked into mainstream L10N stacks.
As localization teams evolve into AI-enhanced language systems, the future lies in choosing the right reasoning model for the job.
Localization is evolving from translation to language reasoning.
If your current TMS still thinks in terms of strings and segments, your next-gen AI assistant should be thinking in tone, purpose, and audience.
Great localization doesn’t just translate. It questions: “Is this the right thing to say—for this market, in this moment?”
In the next edition of The AI-Ready Localizer, I’ll unpack Custom GPTs, Action GPTs, and how a fully AI-driven localization stack—fueled by RAG models—might actually work in practice.
This is so well explained. Enjoyed the post and registered every bit of it. Especially the summary table covers all of it in one place. Thank you Julia.